作业一 Word2Vec&TranE的实现
1 任务目标
1.1 案例简介
Word2Vec是词嵌入的经典模型,它通过词之间的上下文信息来建模词的相似度。TransE是知识表示学习领域的经典模型,它借鉴了Word2Vec的思路,用“头实体+关系=尾实体”这一简单的训练目标取得了惊人的效果。本次任务要求在给定的框架中分别基于Text8和Wikidata数据集实现Word2Vec和TransE,并用具体实例体会词向量和实体/关系向量的含义。
1.2 Word2Vec实现
在这个部分,你需要基于给定的代码实现Word2Vec,在Text8语料库上进行训练,并在给定的WordSim353数据集上进行测试
WordSim353是一个词语相似度基准数据集,在WordSim353数据集中,表格的第一、二列是一对单词,第三列中是该单词对的相似度的人工打分(第三列也已经被单独抽出为ground_truth.npy)。我们需要用我们训练得到的词向量对单词相似度进行打分,并与人工打分计算相关性系数,总的来说,越高的相关性系数代表越好的词向量质量。
我们提供了一份基于gensim的Word2Vec实现,请同学们阅读代码并在Text8语料库上进行训练, 关于gensim的Word2Vec模型更多接口和用法,请参考[2]。
由于gensim版本不同,模型中的size参数可能需要替换为vector_size(不报错的话不用管)
运行word2vec.py 后,模型会保存在word2vec_gensim中,同时代码会加载WordSim353数据集,进行词对相关性评测,得到的预测得分保存在score.npy文件中
之后在Word2Vec文件夹下运行 python evaluate.py score.npy, 程序会自动计算score.npy 和ground_truth.npy 之间的相关系数得分,此即为词向量质量得分。
-
任务
-
运行
word2vec.py训练Word2Vec模型, 在WordSim353上衡量词向量的质量。 -
探究Word2Vec中各个参数对模型的影响,例如词向量维度、窗口大小、最小出现次数。
-
(选做)对Word2Vec模型进行改进,改进的方法可以参考[3],包括加入词义信息、字向量和词汇知识等方法。请详细叙述采用的改进方法和实验结果分析。
-
-
快速上手(参考)
在Word2Vec文件夹下运行
python word2vec.py, 即可成功运行, 运行生成两个文件 word2vec_gensim和score.npy。
1.3 TransE实现
这个部分中,你需要根据提供的代码框架实现TransE,在wikidata数据集训练出实体和关系的向量表示,并对向量进行分析。
在TransE中,每个实体和关系都由一个向量表示,分别用
h
,
r
,
t
h, r,t
h,r,t表示头实体、关系和尾实体的表示向量,首先对这些向量进行归一化
h
=
h
/
∣
∣
h
∣
∣
r
=
r
/
∣
∣
r
∣
∣
t
=
t
/
∣
∣
t
∣
∣
h=h/||h|| \\ r=r/||r||\\ t=t/||t||
h=h/∣∣h∣∣r=r/∣∣r∣∣t=t/∣∣t∣∣
则得分函数(score function)为
f
(
h
,
r
,
t
)
=
∣
∣
h
+
r
−
t
∣
∣
f(h,r,t)=||h+r-t||
f(h,r,t)=∣∣h+r−t∣∣
其中
∣
∣
⋅
∣
∣
||\cdot||
∣∣⋅∣∣表示向量的范数。得分越小,表示该三元组越合理。
在计算损失函数时,TransE采样一对正例和一对负例,并让正例的得分小于负例,优化下面的损失函数
L
=
∑
(
h
,
r
,
t
)
∈
Δ
,
(
h
′
,
r
′
,
t
′
)
∈
Δ
′
max
(
0
,
[
γ
+
f
(
h
,
r
,
t
)
−
f
(
h
′
,
r
′
,
t
′
)
]
)
\mathcal{L}=\sum_{(h,r,t)\in\Delta,(h',r',t')\in\Delta'}\max\left( 0, [\gamma+f(h,r,t)-f(h',r',t')]\right)
L=(h,r,t)∈Δ,(h′,r′,t′)∈Δ′∑max(0,[γ+f(h,r,t)−f(h′,r′,t′)])
其中
(
h
,
r
,
t
)
,
(
h
′
,
r
′
,
t
′
)
(h,r,t), (h',r',t')
(h,r,t),(h′,r′,t′)分别表示正例和负例,
γ
\gamma
γ是一个超参数(margin),用于控制正负例的距离。
-
任务
-
在文件
TransE.py中,你需要补全TransE类中的缺失项,完成TransE模型的训练。需要补全的部分为:_calc():计算给定三元组的得分函数(score function)loss():计算模型的损失函数(loss function)
-
完成TransE的训练,得到实体和关系的向量表示,存储在
entity2vec.txt和relation2vec.txt中。 -
给定头实体Q30,关系P36,最接近的尾实体是哪些?
-
给定头实体Q30,尾实体Q49,最接近的关系是哪些?
-
在 https://www.wikidata.org/wiki/Q30 和 https://www.wikidata.org/wiki/Property:P36 中查找上述实体和关系的真实含义,你的程序给出了合理的结果吗?请分析原因。
-
(选做)改变参数
p_norm和margin,重新训练模型,分析模型的变化。
-
-
快速上手(参考)
在TransE文件夹下运行
python TransE.py, 可以看到程序在第63行和第84行处为填写完整而报错,将这两处根据所学知识填写完整即可运行成功代码(任务第一步),然后进行后续任务。
1.4 评分标准
请提交代码和实验报告,评分将从代码的正确性、报告的完整性和任务的完成情况等方面综合考量。
1.5 参考资料
[1] https://en.wikipedia.org/wiki/Spearman%27s_rank_correlation_coefficient
[2] https://radimrehurek.com/gensim/models/word2vec.html
[3] A unified model for word sense representation and disambiguation. in Proceedings of EMNLP, 2014.
[4] rayo61/NLP-training1-word2vec-TransE: This is the experiment and report of NLP training course of Xuetangzaixian (github.com)
2 Word2Vec 实现
2.1 Word2Vec 基本原理
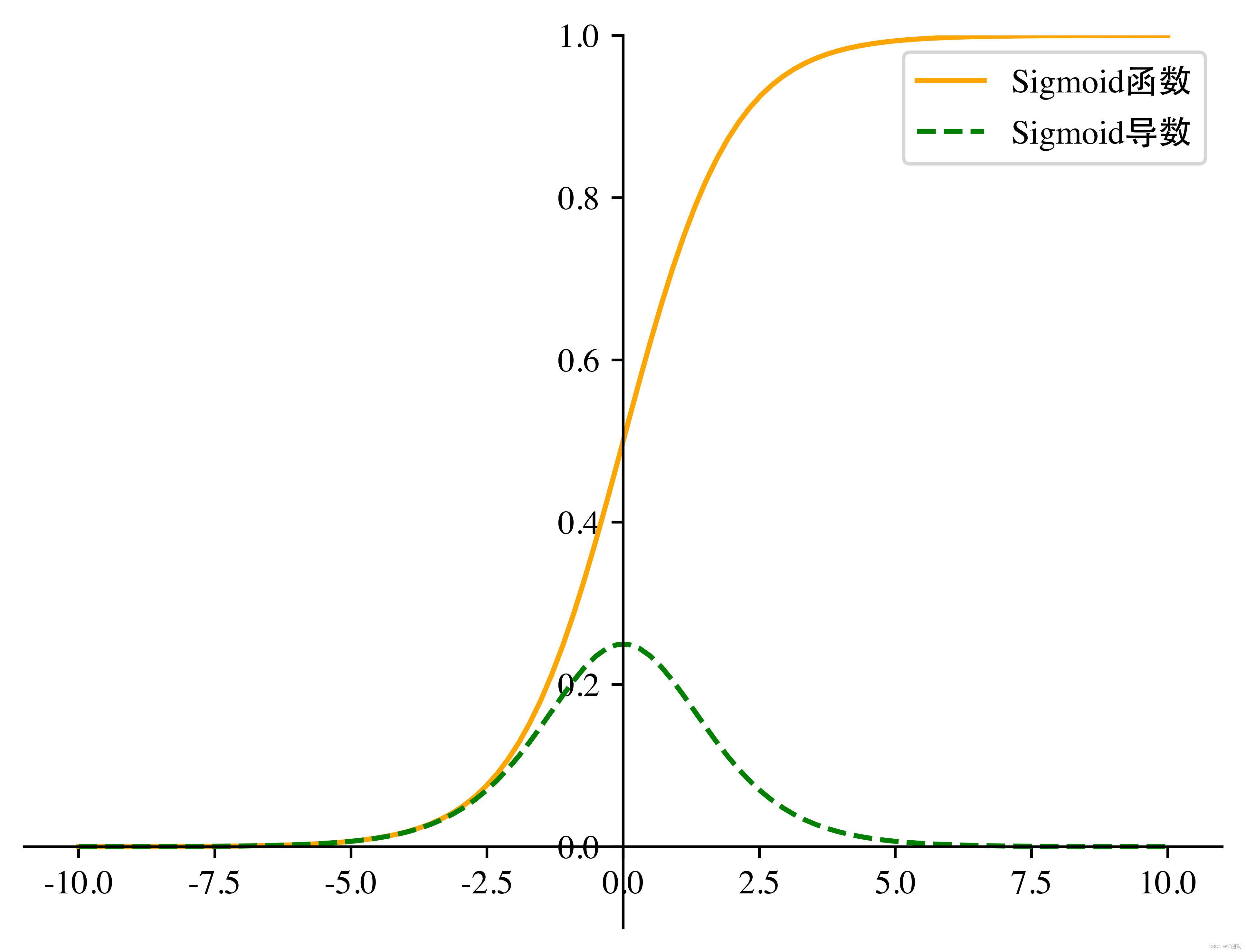
Word2Vec 是一种用于生成单词嵌入(word embeddings)的计算模型,由 Google 的研究人员在 2013 年提出。它属于无监督学习算法,可以从大量文本数据中学习到 单词的向量表示 。Word2Vec 的核心思想是捕捉 单词之间的语义和句法 关系,使得在向量空间中,语义上相似的单词会有相近的向量表示。
Word2Vec 通过 滑动窗口 实现,word2vec使用一个固定大小的窗口沿着句子滑动。在每一个窗口中,中间的词作为目标词,其他的词作为上下文。下图为滑动窗口为5时的训练示例。

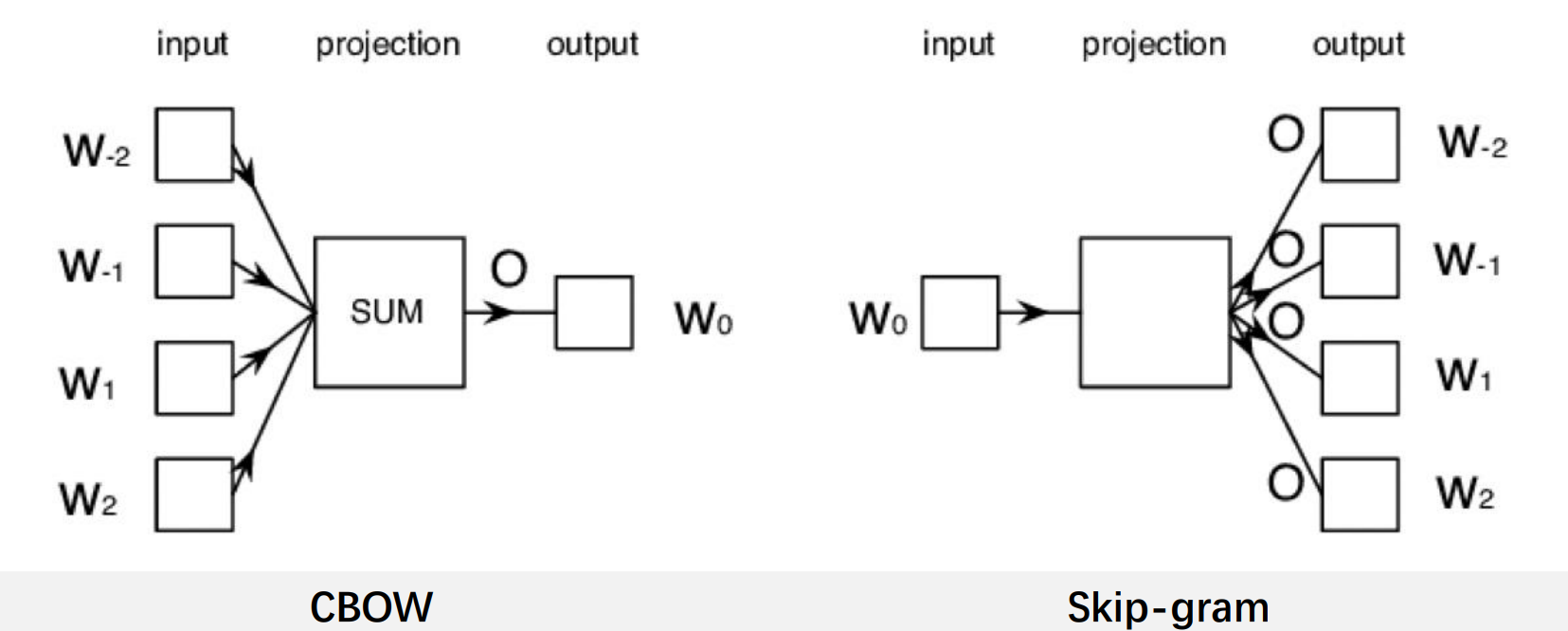
Word2Vec 主要有两种架构:连续词袋(Continuous Bag of Words, CBOW)和跳跃式模型(Skip-Gram)。
-
连续词袋(CBOW)
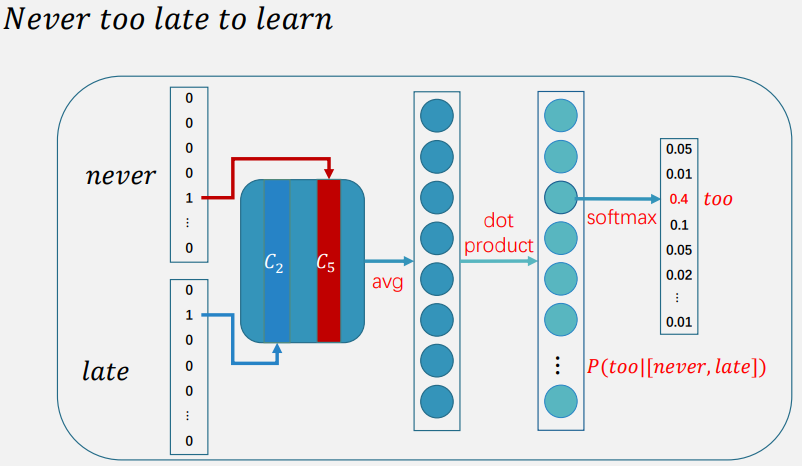
- 在 CBOW 模型中,目标是 根据上下文单词预测目标单词 。具体来说,模型会取目标单词周围的上下文单词(例如,前后各 N 个单词),将这些上下文单词的向量表示平均或加权求和,然后使用这个综合向量来预测目标单词。
- 通过词袋假设,假设上下文词的顺序不影响模型的预测结果。
- 这种模型适合于较小的词汇表和较短的上下文窗口,可以快速训练。
-
跳跃式模型(Skip-Gram)
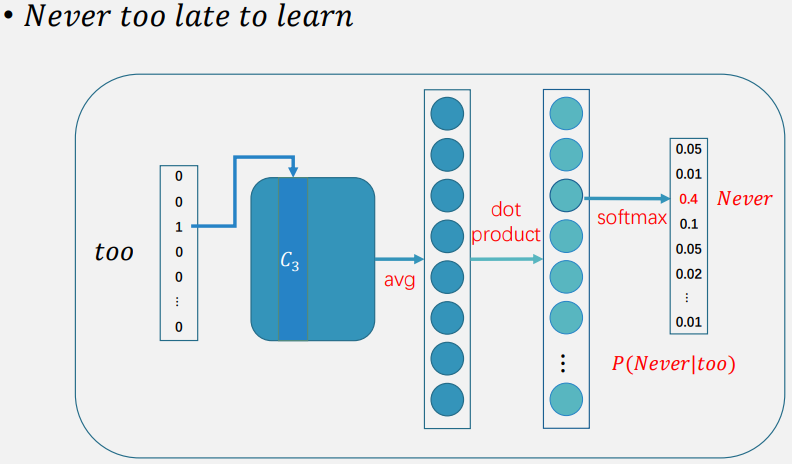
- 在 Skip-Gram 模型中,目标是 使用单个目标单词来预测整个上下文中的单词 。也就是说,给定一个目标单词,模型需要预测它可能出现的上下文。
- Skip-Gram 通常比 CBOW 更准确,特别是对于更大词汇表和更长的上下文窗口。它在小数据集上表现更好,但在处理大量数据时训练速度较慢。
2.2 代码实现
Word2Vec 实验中,已给出了完整的实验代码,无需自己补充。实验使用 gensim 库来训练一个 Word2Vec 模型,并对其进行评估的示例。代码包括数据加载、模型训练、模型保存以及在标准测试集上的评估,下面介绍代码的主要部分。
-
训练 Word2Vec 模型
实验使用
word2vec.Text8Corpus函数加载文本数据集。然后通过gensim.models.Word2Vec创建 Word2Vec 模型进行训练,并传入了加载的语料库sents。# loading dataset sents = word2vec.Text8Corpus(data_path) # training word2vec model = gensim.models.Word2Vec(sents, vector_size=200, window=10, min_count=10, workers=multiprocessing.cpu_count())vector_size参数设置为 200,表示每个单词向量的维度。window参数设置为 10,表示考虑的上下文窗口大小。min_count参数设置为 10,表示忽略频率低于 10 的单词。workers参数设置为multiprocessing.cpu_count(),表示使用 CPU 的核心数进行并行计算。
这里未设置模型参数
sg,默认使用CBOW(sg=0)进行训练。 -
模型保存
# saving to file model.save("word2vec_gensim") model.wv.save_word2vec_format("word2vec_org", "vocabulary", binary=False) print ("Total time: %d s" % (time() - t))- 使用
model.save方法将训练好的 Word2Vec 模型保存到文件 “word2vec_gensim”。 - 使用
model.wv.save_word2vec_format方法将模型的词向量以 Word2Vec 格式保存到 “word2vec_org” 文件中,同时保存词汇表到 “vocabulary” 文件中,并且设置binary=False以保存为文本格式。
- 使用
-
模型测试
在 wordsim353 数据集上测试模型。
# testing on wordsim353 sims = [] ground_truth = [] with open('wordsim353/combined.csv') as f: for line in f.readlines()[1:]: l = line.strip().split(',') if l[0] in model.wv.key_to_index and l[1] in model.wv.key_to_index: # 过滤掉不在词表内的词 sims.append(model.wv.similarity(l[0], l[1])) # 模型打分 ground_truth.append(float(l[2])) np.save('score.npy', np.array(sims)) np.save('ground_truth.npy', np.array(ground_truth))- 初始化两个空列表
sims和ground_truth,分别用于存储模型计算的相似度分数和 ground truth(真实)分数。 - 打开 ‘wordsim353/combined.csv’ 文件,并读取除标题外的所有行。
- 对每一行进行处理,首先去除前后的空白字符,然后使用
split(',')按逗号分割。 - 检查两个单词是否都在模型的词汇表中,如果是,则使用
model.wv.similarity方法计算这两个单词的相似度,并将其添加到sims列表中。 - 同时,将该行的第三个元素(相似度分数)转换为浮点数,并添加到
ground_truth列表中。 - 使用
numpy.save方法将sims和ground_truth列表保存为.npy文件,这些文件可以用于后续的评估和分析。
- 初始化两个空列表
2.3 项目训练
本次训练采用在本地进行训练,下面介绍具体训练流程。
-
数据集
本实验采用了两个数据集,在 Text8语料库 上进行训练,并在给定的 WordSim353数据集 上进行测试。
-
Text8语料库
Text8 数据集仅包含小写英文字母、空格以及数字被转换成了对应的英文单词,去除了所有的标点符号和非英文字符。其包含了从 Wikipedia 抓取的前 100,000,000 个字符,部分内容如下:
anarchism originated as a term of abuse first used against early working class radicals including the diggers of the english revolution and the sans culottes of the french revolution whilst the term is still used in a pejorative way to describe any act that used violent means to destroy the organization of society it has also been taken up as a positive label by self defined anarchists the word ... -
WordSim353数据集
WordSim-353 数据集是一个用于评估英语单词对相似性或相关性的测试集合。它包含了两组英语单词对 set1 和 set2,以及由人类评估者赋予的相似性分数。数据集文件组成如下:
──wordsim353 combined.csv combined.tab instructions.txt set1.csv set1.tab set2.csv set2.tab-
第一组(set1)包含 153 对单词对,以及由 13 名评估者赋予的相似性分数。
Word 1 Word 2 Human (mean) 1 2 3 4 5 6 7 8 9 10 11 12 13 love sex 6.77 9 6 8 8 7 8 8 4 7 2 6 7 8 tiger cat 7.35 9 7 8 7 8 9 8.5 5 6 9 7 5 7 tiger tiger 10.00 10 10 10 10 10 10 10 10 10 10 10 10 10 book paper 7.46 8 8 7 7 8 9 7 6 7 8 9 4 9 ... -
第二组(set2)包含 200 对单词对,由另外 16 名评估者评估。
Word 1 Word 2 Human (mean) 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 energy secretary 1.81 1 0 4 2 4 5 1 1 1 0 1 1 4 0 2 2 secretary senate 5.06 7 1 7 4 4 7 1 3 4 8 4 5 6 7 6 7 energy laboratory 5.09 7 1 7.5 4 6 7 4 6 1 2 4 3 7 9 6 7 computer laboratory 6.78 8 5 8 7 6 9 6 7 6 7.5 4 5 8 9 7 6 ... -
结合(combined)将 set1 和 set2 集合并成一个单一的集合
Word 1 Word 2 Human (mean) love sex 6.77 tiger cat 7.35 tiger tiger 10.00 book paper 7.46 ...
-
-
-
代码训练
修改代码中
data_path的路径,改为text8的本地相对路径。跳转到 Word2Vec 文件夹下,输入以下指令开始训练。python word2vec.py看到以下内容,说明训练成功开始。
训练结束后,显示如下内容。
2024-04-25 11:06:10,798 : INFO : Word2Vec lifecycle event {'msg': 'training on 85026035 raw words (61669556 effective words) took 66.9s, 922157 effective words/s', 'datetime': '2024-04-25T11:06:10.798335', 'gensim': '4.3.2', 'python': '3.11.5 | packaged by Anaconda, Inc. | (main, Sep 11 2023, 13:26:23) [MSC v.1916 64 bit (AMD64)]', 'platform': 'Windows-10-10.0.19043-SP0', 'event': 'train'} 2024-04-25 11:06:10,799 : INFO : Word2Vec lifecycle event {'params': 'Word2Vec<vocab=47134, vector_size=200, alpha=0.025>', 'datetime': '2024-04-25T11:06:10.799334', 'gensim': '4.3.2', 'python': '3.11.5 | packaged by Anaconda, Inc. | (main, Sep 11 2023, 13:26:23) [MSC v.1916 64 bit (AMD64)]', 'platform': 'Windows-10-10.0.19043-SP0', 'event': 'created'} 2024-04-25 11:06:10,800 : INFO : Word2Vec lifecycle event {'fname_or_handle': 'word2vec_gensim', 'separately': 'None', 'sep_limit': 10485760, 'ignore': frozenset(), 'datetime': '2024-04-25T11:06:10.800330', 'gensim': '4.3.2', 'python': '3.11.5 | packaged by Anaconda, Inc. | (main, Sep 11 2023, 13:26:23) [MSC v.1916 64 bit (AMD64)]', 'platform': 'Windows-10-10.0.19043-SP0', 'event': 'saving'} 2024-04-25 11:06:10,812 : INFO : not storing attribute cum_table 2024-04-25 11:06:10,929 : INFO : saved word2vec_gensim 2024-04-25 11:06:10,958 : INFO : storing vocabulary in vocabulary 2024-04-25 11:06:11,009 : INFO : storing 47134x200 projection weights into word2vec_org Total time: 77 s最终存储
vocabulary,score.npy,ground_truth.npy文件。 -
代码测试
本实验通过
evaluation.py计算 Spearman 相关系数 ,它用于评估 Word2Vec 模型生成的单词相似度分数与真实分数之间的相关性。def eval(submit_file): sims = np.load(submit_file[1]) score = np.load('ground_truth.npy') # 计算Spearman相关系数 spcor = spearmanr(score, sims)[0] # 以下返回值主要用于aistudio的比赛,但是本次实验不设置比赛,大家只用看score的值 return { "score": spcor, #替换value为最终评测分数 "errorMsg": "success", #错误提示信息,仅在code值为非0时打印 "code": 0, #code值为0打印score,非0打印errorMsg "data": [ { "score": spcor } ] }输入如下指令,运行
evaluation.py测试代码,进行测试。python evaluation.py score.npy得到的结果如下。
{"score": 0.6886039757987104, "errorMsg": "success", "code": 0, "data": [{"score": 0.6886039757987104}]}得到了 score 的值为 0.6886。
2.4 参数对模型的影响
本部分实验从 词向量维度、窗口大小、最小出现次数 三个维度对比其对模型的影响。
-
词向量维度(vector_size)
实验分别选择了 50,100,150,200,250,300 的词向量维度,其他值选择默认值,即 window=10,min_count=10,进行实验。记录得到 score 与耗费的时间 time,结果如下。
score = [0.6606661257461373, 0.692237913064484, 0.6924479511296131, 0.6951971378884105, 0.6807892808556052, 0.6903557686853921] time = [21, 57, 75, 96, 98, 51]用折线图的形式表示,结果如下。
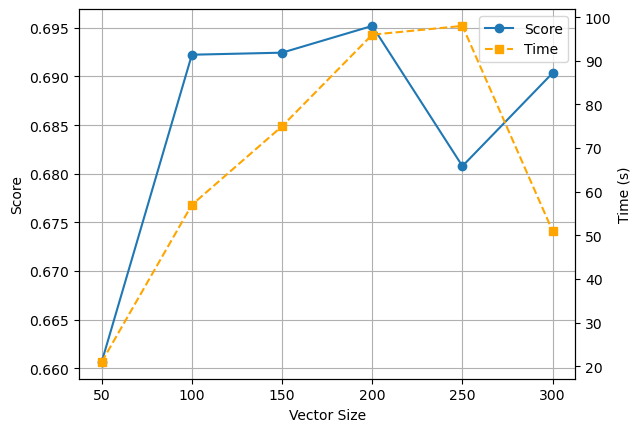
可以看出,随着词向量维度的增加,训练时间逐步增加,直到300出现骤降。而 Score 在 0.66-0.7 之间波动,在词向量维度为200时,Score达到最大值 0.6952。
-
窗口大小(window)
实验分别选择了 5,10,15,20,25,30 的窗口大小,其他值选择默认值,即 vector_size=200,min_count=10,进行实验。记录得到 score 与耗费的时间 time,结果如下。
score = [0.6440411455933666, 0.684678346325392, 0.7034369918501572, 0.7132489339996146, 0.7193900469514843, 0.7170033849093149] time = [50, 49, 44, 45, 42, 47]用折线图的形式表示,结果如下。
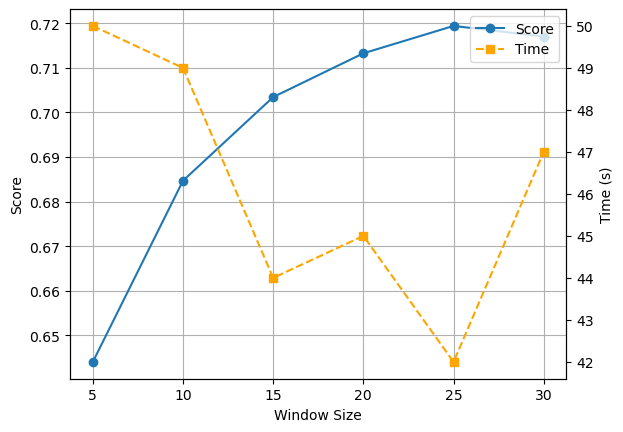
可以看出,随着窗口大小的增加,训练时间在40-50之间波动。而 Score 在逐步上升,在窗口大小为25时,Score达到最大值 0.7194。
-
最小出现次数(min_count)
实验分别选择了 5,10,15,20,25,30 的最小出现次数,其他值选择默认值,即 vector_size=200,window=10,进行实验。记录得到 score 与耗费的时间 time,结果如下。
score = [0.6927590997286565, 0.6934430495037492, 0.6904133055101986, 0.6893439535738417, 0.704707239257633, 0.6936508753087103] time = [44, 39, 36, 35, 33, 33]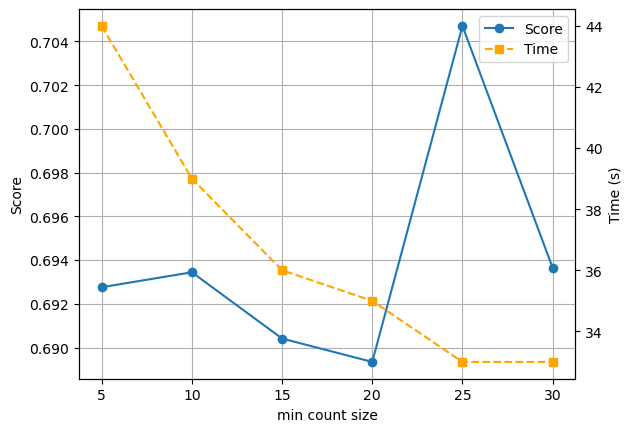
可以看出,随着最小出现次数的增加,训练时间在逐步减小。而 Score 在0.69-0.71之间波动,在最小出现次数为25时,Score达到最大值 0.7047。
2.5 实验改进
本实验改进,和在 vector_size=200, window=10, min_count=10 参数下的模型,进行比较。其运行时长为 77 s , score 为 0.6886 。
-
使用 Skip-Gram 进行训练
在
gensim.models.Word2Vec中添加参数sg=1,表示使用 Skip-Gram 进行训练,其他参数保持不变,即 vector_size=200, window=10, min_count=10。训练结果如下。Total time: 147 s "score": 0.7124438700653573可以看到训练时间变得更长,相比于使用 CBOW 模式训练,score 从 0.6886 提升到了 0.7124。
-
增长训练轮次
默认训练 5 轮,增加到 10 轮,训练结果如下。
Total time: 104 s "score": 0.7277341821071591可以看到增长训练轮次,有效的提升了 score 值,同时增加了训练时长。
3 TransE 实现
3.1 TransE 原理
TransE 是一种知识图谱嵌入(Knowledge Graph Embedding, KGE)模型,由 Antoine Bordes 等人在 2013 年提出。它的目标是将知识图谱中的实体(entities)和关系(relations)映射到连续的向量空间中,使得可以通过向量运算来推断实体间的关系。
TransE 模型的核心思想是,对于一个三元组(头实体h-关系r-尾实体t),例如 (华盛顿,首都,美国),TransE 试图通过将头实体的向量与关系向量相加,然后减去尾实体的向量,来使得三元组的得分尽可能高。换句话说,TransE 模型试图在向量空间中捕捉头实体和尾实体通过关系相连的事实。

3.2 代码实现
实验给了一个 TransE 模型训练和评估的代码 TransE.py,需要补齐 _calc , loss 方法的代码。
-
配置类(
Config)定义了模型训练的超参数,包括范数类型、隐藏层大小、批次数量、实体和关系的总数、训练次数、边界值、学习率以及是否使用GPU。
class Config(object): def __init__(self): self.p_norm = 1 self.hidden_size = 50 self.nbatches = 100 self.entity = 0 self.relation = 0 self.trainTimes = 100 self.margin = 0.5 self.learningRate = 0.01 self.use_gpu = False根据是否使用GPU,将numpy数组转换为PyTorch的
Variable对象,以便在GPU上进行计算。def to_var(x, use_gpu): if use_gpu: return Variable(torch.from_numpy(x).cuda()) else: return Variable(torch.from_numpy(x)) -
TransE模型类 (
TransE)该代码继承自
torch.nn.Module,实现TransE模型的核心逻辑。-
得分函数(
_calc)根据 头实体h ,尾实体t 和 关系r 的嵌入向量,计算TransE的得分函数。
def _calc(self, h, t, r): # TO DO: implement score function # Hint: you can use F.normalize and torch.norm functions if self.norm_flag: # normalize embeddings with l2 norm h = F.normalize(h,p = self.p_norm,dim = 1) t = F.normalize(t,p = self.p_norm,dim = 1) r = F.normalize(r,p = self.p_norm,dim = 1) score = torch.norm( h + r - t,self.p_norm,dim = 1) return score -
前向传播(
forward)定义了模型的前向传播过程,接受输入数据,计算得分。
def forward(self, data): batch_h = data['batch_h'] batch_t = data['batch_t'] batch_r = data['batch_r'] h = self.ent_embeddings(batch_h) t = self.ent_embeddings(batch_t) r = self.rel_embeddings(batch_r) score = self._calc(h ,t, r) return score -
预测函数(
predict)通过前向传播将模型的预测得分转换为numpy数组并返回。
def predict(self, data): score = self.forward(data) return score.cpu().data.numpy() -
损失函数(
loss)实现了带有边界的损失函数,使用ReLU激活函数确保损失值非负。
def loss(self, pos_score, neg_score): # TO DO: implement loss function # Hint: consider margin return torch.nn.ReLU()(self.margin + (pos_score - neg_score).mean())
-
-
主函数(
main)-
创建配置对象和数据加载器
PyTorchTrainDataLoader。config = Config() train_dataloader = PyTorchTrainDataLoader( in_path = "./data/", nbatches = config.nbatches, threads = 8) -
实例化TransE模型,并根据配置设置其参数。
transe = TransE( ent_tot = train_dataloader.get_ent_tot(), rel_tot = train_dataloader.get_rel_tot(), dim = config.hidden_size, p_norm = config.p_norm, norm_flag = True, margin=config.margin) -
选择优化器,如果是GPU环境则迁移模型到GPU上。
optimizier = optim.SGD(transe.parameters(), lr=config.learningRate) if config.use_gpu: transe.cuda() -
迭代训练
每次迭代都通过数据加载器获取数据,计算损失,执行反向传播并更新模型参数。
for times in range(config.trainTimes): ep_loss = 0. for data in train_dataloader: optimizier.zero_grad() score = transe({ 'batch_h': to_var(data['batch_h'], config.use_gpu).long(), 'batch_t': to_var(data['batch_t'], config.use_gpu).long(), 'batch_r': to_var(data['batch_r'], config.use_gpu).long()}) pos_score, neg_score = score[0], score[1] loss = transe.loss(pos_score, neg_score) loss.backward() optimizier.step() ep_loss += loss.item() print("Epoch %d | loss: %f" % (times+1, ep_loss)) print("Finish Training") -
训练完成后,将实体和关系的嵌入向量保存到文本文件中。
f = open("entity2vec_margin1.txt", "w") enb = transe.ent_embeddings.weight.data.cpu().numpy() for i in enb: for j in i: f.write("%f\t" % (j)) f.write("\n") f.close() f = open("relation2vec_margin1.txt", "w") enb = transe.rel_embeddings.weight.data.cpu().numpy() for i in enb: for j in i: f.write("%f\t" % (j)) f.write("\n") f.close()
-
3.3 项目训练
本次项目是在本地进行训练,下面介绍具体训练流程。
-
数据集
本实验采用 wikidata数据集 ,包含大量的数据项和关系,构成了庞大的三元组集合,这些三元组由主语(实体)、谓语(关系)和宾语(实体或值)组成。
-
entity2id(实体到ID的映射)
一个具有50000行的实体到ID映射的数据集,以Q开头的 wikidata实体 与其对应ID组成,内容如下。
50000 Q18285162 38039 Q209118 47236 Q24297027 36800 Q312001 46250 Q18844919 34546 ...其中可以根据以下格式网址
https://www.wikidata.org/wiki/Q30,查找以Q开头实体表示的具体内容。 -
relation2id(关系到ID的映射)
一个具有378行的关系到ID映射的数据集,以P开头的 wikidata关系 与其对应ID组成,内容如下。
378 P126 278 P2789 261 P541 353 P1462 183 P2388 311 ...其中可以根据以下格式网址
https://www.wikidata.org/wiki/Property:P36,查找以P开头关系表示的具体内容。 -
triple2id(三元组到ID的映射)
一个具有299291行的三元组(头实体、关系、尾实体)数据集,由三列ID组成,第一列为头实体ID,第二列为尾实体ID,第三列为关系ID。
299291 49082 10984 0 49082 47288 0 49082 230 1 49082 21973 2 49082 217 2 ...可以映射表找到ID表示内容,如第一行头实体ID为 49082 映射到 Q23,在wikidata表示为 George Washington;尾实体ID为 10984 映射到 Q40949,在wikidata表示为 American Revolutionary War;关系ID为 0 映射到 P607,在wikidata表示为 conflict。第一行的即表示了(George Washington, conflict, American Revolutionary War) 的三元组,表示了 乔治华盛顿 与 美国独立战争 的关系是 军事冲突 。
-
-
代码训练
采用基础参数进行训练,训练100轮次,执行以下指令,运行
TransW.py代码,开始训练。python TransE.py训练结果如下。
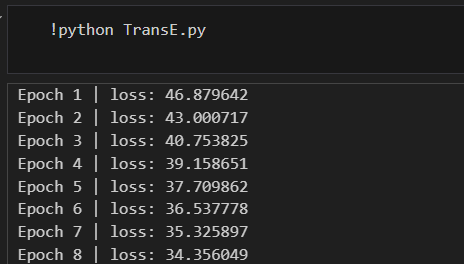
一个训练了100轮,从第一轮的 loss 值46.879642,下降到最后一轮的0.000000,用折线图表示如下。
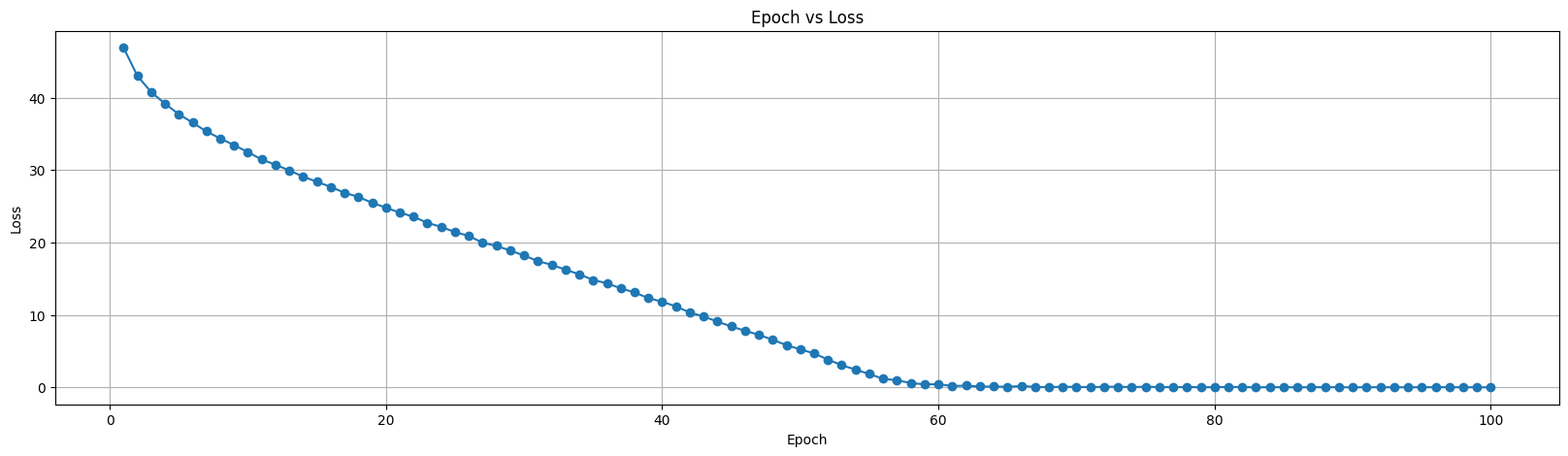
可以看到经过100轮训练,loss值有效的下降。
训练结束后,得到两个文件
entity2vec_margin1.txt与relation2vec_margin1.txt分别保存了实体和关系的向量表示。
3.4 项目测试
-
代码设计
可以通过将头实体的向量与关系向量相加,然后减去尾实体的向量,来计算三元组的得分,以下为测试代码。
-
初始化模型
#初始化模型 config = Config() train_dataloader = PyTorchTrainDataLoader( in_path = "./data/", nbatches = config.nbatches, threads = 8) transe = TransE( ent_tot = train_dataloader.get_ent_tot(), rel_tot = train_dataloader.get_rel_tot(), dim = config.hidden_size, #50 p_norm = config.p_norm, norm_flag = True, margin=config.margin) -
初始化wikidata词条与embedding序号之间的字典
#初始化wikidata词条与embedding序号之间的字典 ent_dic = {} rel_dic = {} f = open('./data/entity2id.txt','r') next(f) for index in range(train_dataloader.get_ent_tot()): value,key = f.readline().strip().split() ent_dic[int(key)] = value f = open('./data/relation2id.txt','r') next(f) for index in range(train_dataloader.get_rel_tot()): value,key = f.readline().strip().split() rel_dic[int(key)] = value -
载入预训练的embedding参数
将预先训练好的嵌入参数(embeddings)加载到TransE模型中。
#载入预训练的embedding参数 ent_data = np.loadtxt('entity2vec_margin1.txt') rel_data = np.loadtxt('relation2vec_margin1.txt') ent_data = torch.Tensor(ent_data) rel_data = torch.Tensor(rel_data) transe.ent_embeddings = transe.ent_embeddings.from_pretrained(ent_data) transe.rel_embeddings = transe.rel_embeddings.from_pretrained(rel_data)
-
-
代码测试
根据以下两个案例,对训练得到的模型进行测试。
-
给定头实体Q30,关系P36,最接近的尾实体是哪些?
查询 wikidata 网址,Q30为 United States of America,P36 为 capital 。预测尾实体代码如下:
#预测Q30+P36最接近的尾实体 data = {'batch_h':torch.LongTensor([list(ent_dic.keys())[list(ent_dic.values()).index('Q30')]]), 'batch_r':torch.LongTensor([list(rel_dic.keys())[list(rel_dic.values()).index('P36')]]), 'batch_t':torch.LongTensor([i for i in range(train_dataloader.get_ent_tot())])} score = transe.predict(data) for index in score.argsort()[0:10]: print(ent_dic[index])以上代码采用预测函数
transe.predict(data),得到前10个最匹配的尾实体,结果如下所示: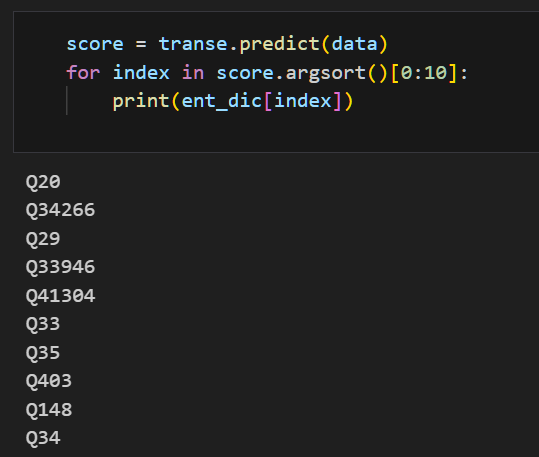
实体ID 含义 解释 Q20 Norway country in Northern Europe Q34266 Russian Empire former empire in Eurasia and North America (1721–1917) Q29 Spain country in southwestern Europe with territories in Africa Q33946 Czechoslovakia country in Central Europe, 1918–1992 Q41304 Weimar Republic Germany in the years 1918/1919–1933 Q33 Finland country in Northern Europe Q35 Denmark country in Northern Europe Q403 Serbia country in Southeast Europe Q148 People’s Republic of China country in East Asia Q34 Sweden country in Northern Europe 可以看到,前10的实体大部分为国家,如挪威、俄罗斯等。应该得到的尾实体为Q61 华盛顿,并未在前10实体中出现,说明训练结果推测尾实体的效果并不是很好。
-
给定头实体Q30,尾实体Q49,最接近的关系是哪些?
查询 wikidata 网址,Q30为 United States of America,Q49 为 North America 。预测关系代码如下:
data_1 = {'batch_h':torch.LongTensor([list(ent_dic.keys())[list(ent_dic.values()).index('Q30')]]), 'batch_t':torch.LongTensor([list(ent_dic.keys())[list(ent_dic.values()).index('Q49')]]), 'batch_r':torch.LongTensor([i for i in range(train_dataloader.get_rel_tot())])} score_1 = transe.predict(data_1) for index in score_1.argsort()[0:10]: print(rel_dic[index])以上代码采用预测函数
transe.predict(data_1),得到前10个最匹配的关系,结果如下所示: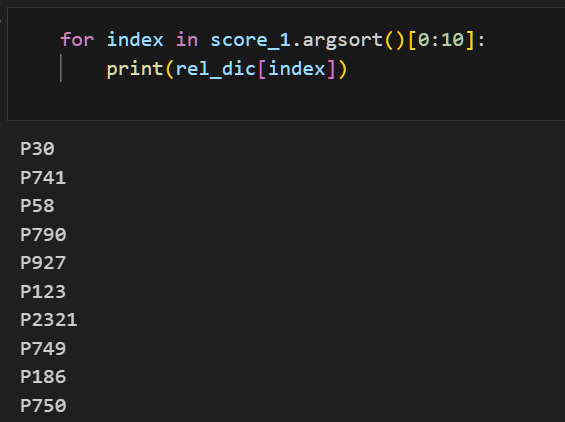
关系ID 含义 解释 P30 continent continent of which the subject is a part P741 playing hand hand used to play a racket sport, cricket, fencing, or curling P58 screenwriter person(s) who wrote the script for subject item P790 approved by item is approved by other item(s) P927 anatomical location where in the body or cell does this feature lie or happen P123 publisher organization or person responsible for publishing books, periodicals, printed music, podcasts, games or software P2321 general classification of race participants classification of race participants P749 parent organization parent organization of an organization, opposite of subsidiaries (P355) P186 made from material material the subject or the object is made of or derived from (do not confuse with P10672 which is used for processes) P750 distributed by distributor of a creative work; distributor for a record label; news agency; film distributor 可以看到,排在第一位的就是 continent 大洲,United States of America 与 North America 的关系是美国属于北美洲,即 continent 这个答案很准确。
-
3.5 代码改进
改变参数p_norm和margin,重新训练模型,分析模型的变化。
-
p_norm对训练模型的影响p_norm决定了得分函数中使用的范数类型。在TransE中,通常使用L1范数(当p_norm=1)或L2范数(当p_norm=2)。-
p_norm=1L1范数(曼哈顿距离)对数据中的噪声和异常值更加鲁棒,但在优化过程中可能会导致较慢的收敛。
在最初的训练中,使用的就是
p_norm=1,训练100轮,用折线图表示loss变化结果如下。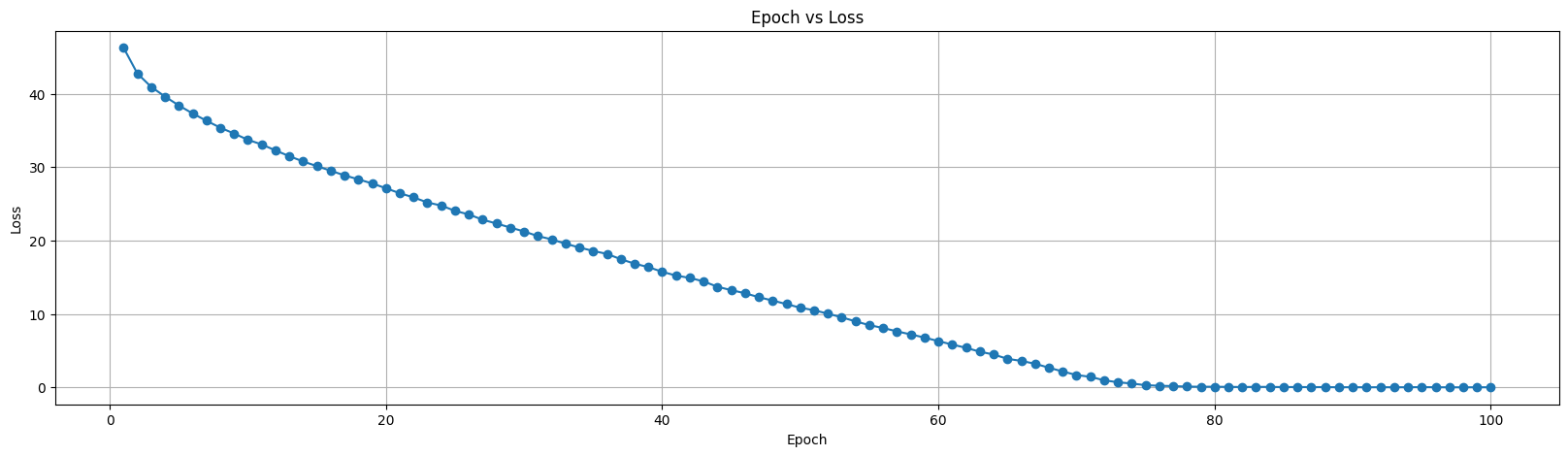
-
p_norm=2L2范数(欧几里得距离)在优化过程中通常更快收敛,但对异常值的敏感度更高。
下图为使用
p_norm=2训练的结果图像,可以看到,使用L2范数收敛过程更快。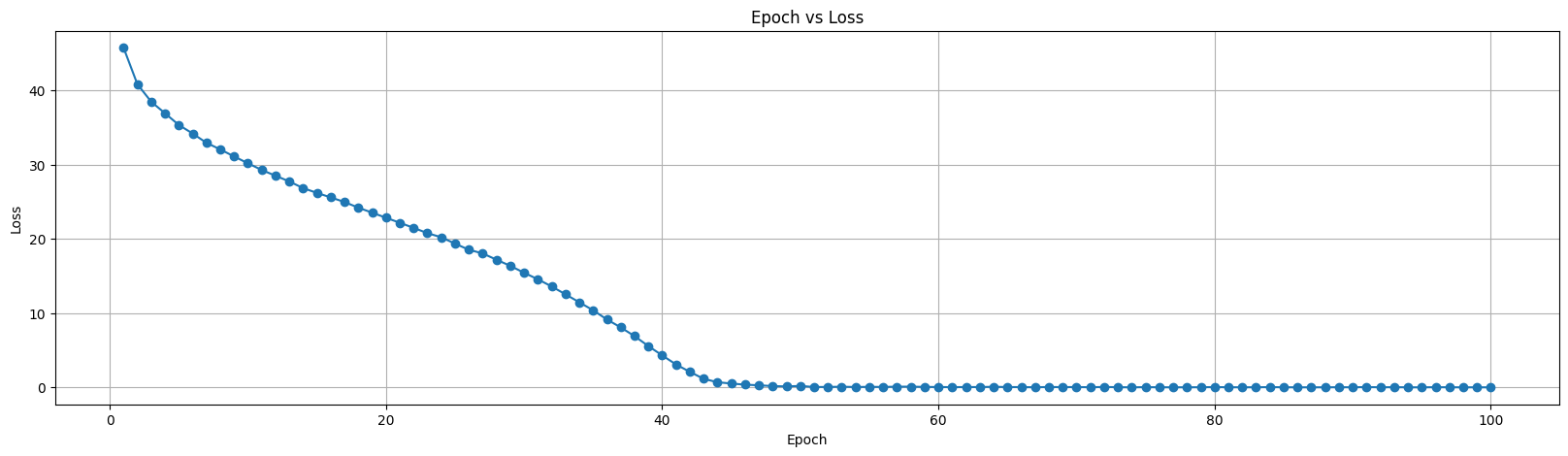
给定头实体Q30,关系P36,尾实体预测值如下。

结果与
p_norm=1时相似,都是预测了一些国家名,如俄罗斯、英国等,没有预测出正确答案华盛顿。给定头实体Q30,尾实体Q49,关系预测值如下。
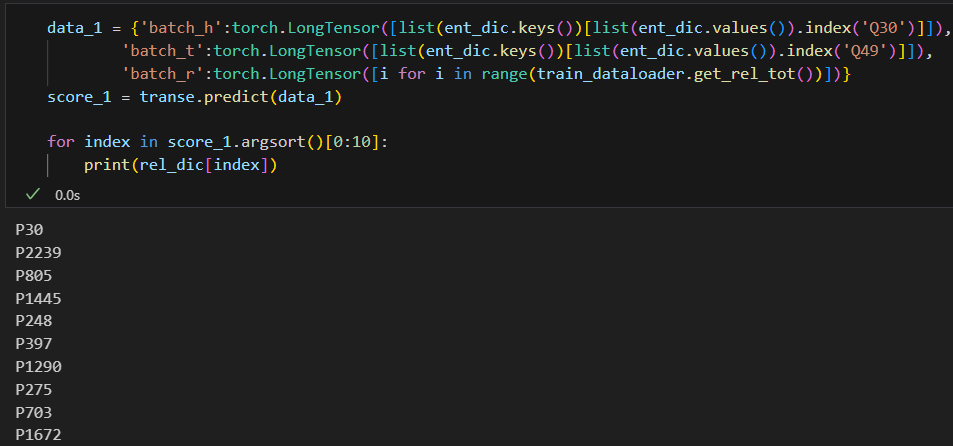
结果与
p_norm=1时相似,在首位就预测出了正确的关系 P30 大洲。
-
-
margin对训练模型的影响margin是TransE损失函数中的一个参数,用于定义正样本和负样本之间的边界。损失函数旨在确保正样本的得分高于负样本的得分至少margin值。实验给的 margin 值为0.5,下面将给出 margin 值为1的训练结果。
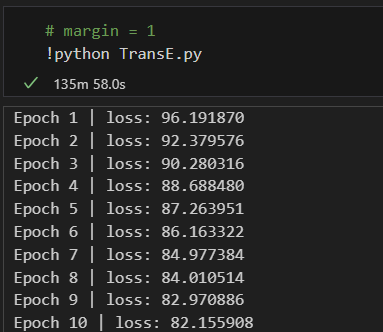
将
margin=0.5与margin=1两组训练结果绘制在折线图中,如下图所示。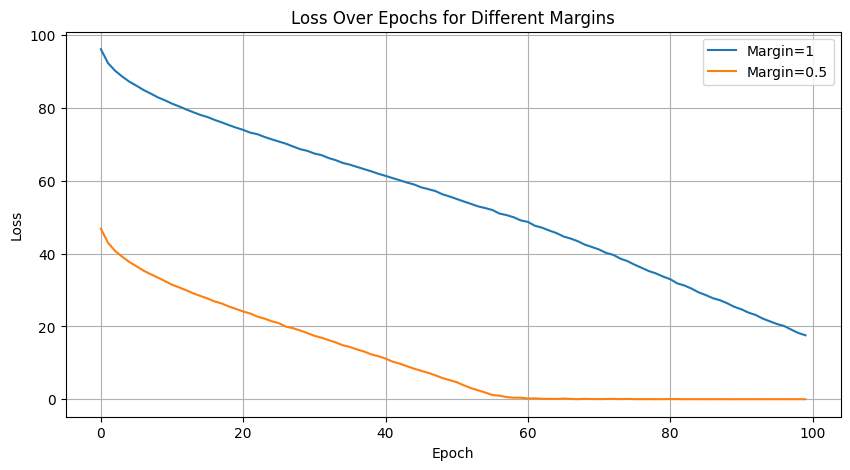
使用
margin=1进行测试,结果如下。-
给定头实体Q30,关系P36,尾实体预测值如下。
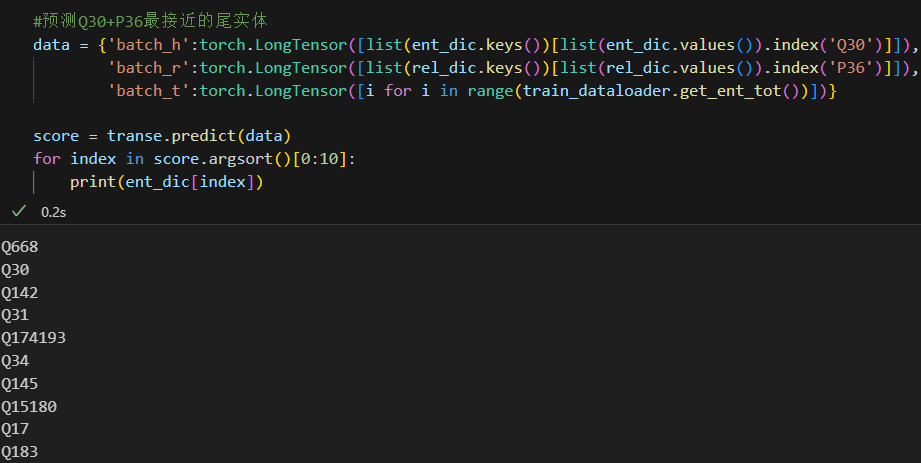
结果与
margin=0.5时相似,都是预测了一些国家名,排名第一的是 Q668 印度,没有预测出正确答案华盛顿。 -
给定头实体Q30,尾实体Q49,关系预测值如下。
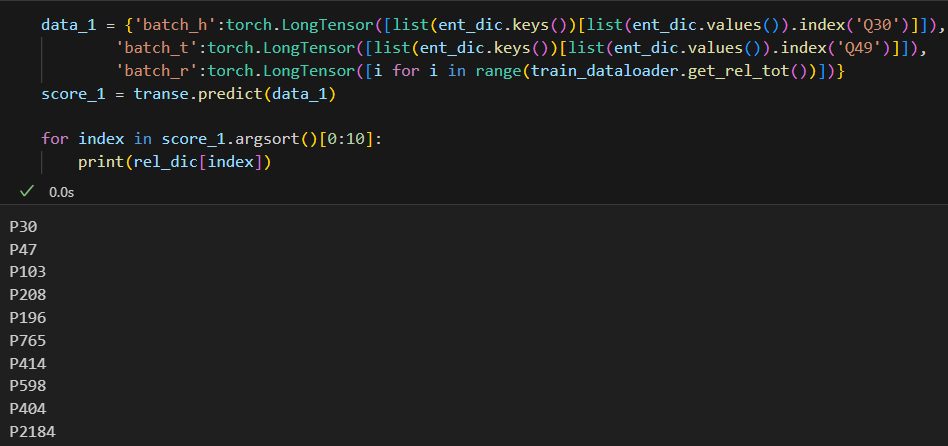
结果与
margin=0.5时相似,在首位就预测出了正确的关系 P30 大洲。
-